
我用jsoup分析了个html页面,但在有些地方页面上

1、你贴的python代码,缩进有问题。
请自行决定代码缩进是否正常,并将正常代码粘贴到我们身上。
2:
在您的代码里处理过的东西,确实是您截屏贴的东西–>节目抓的东西,有时不一定就像看网页源码时所见。
3。您beautifulSoup的使用方法,不是很正确。
jsoup如何获取中的数据
可利用正则表达式进行匹配追问,请问下面若使用正则表达式应怎样书写?
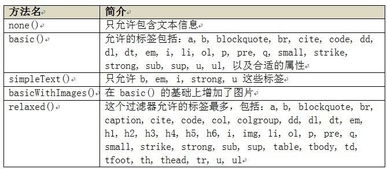
求救如何在html中使用jsoup来分析head
以下为作者编写部分代码.
newsItemBiz public-class {
private static String url = “http://news.iciba .康姆/dailysentence”;
public String getContent() Exception{
Yielding a string of htmlStr = GetHtml.doGet(url);
println(htmlStr) System.out.println;
File doc = Jsoup.parse(htmlStr);
Elemental units = doc.head();
Element comm = units.child(3);
String comString = comm.attr(“content”); String comString = comm.attr(“content”);
println(comString) System.out.println;
back comString;
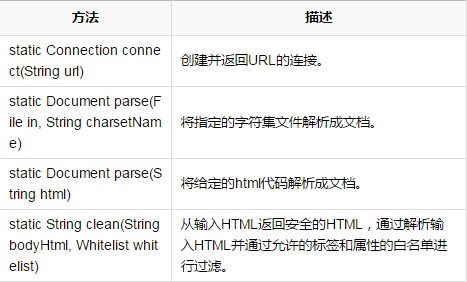
Jsoup.parse和Jsoup.connect方法有什么不同? Jsoup.parse和Jsoup.connect方法有什么不同?
Jsoup.parse解析HTML字符串,如Jsoup.parse(“”) Jsoup.parse解析HTML字符串,如Jsoup.parse(“”)
Jsoup.connect解析url网站地址,如Jsoup.connect(http://www.baidu .康姆).get() Jsoup.connect解析url网站地址,如Jsoup.connect(http://www.baidu .康姆).get()
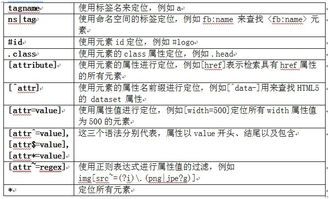
jsoup是如何在一个div下面取东西
Document doc=Jsoup.parse(html),html就是指包含你需要的div的那段html代码,然后再Elements el=doc.select(”div”),如果这个div有class=abc,或者id=abc,或其它性质attr=abc,那么你就这么选,doc.select(”div[AttrName=abc]”),AttrName就是指class,id或其它属性名称,百度不得直接发布链接,因此您最好在Jsoup中重新检索API并阅读,在Selector类中有一个文档例子。
原创文章,作者:聚禄鼎,如若转载,请注明出处:https://www.xxso.cn/10902.html