
搜索引擎的原理

搜索引擎工作原理一共分为四步:
第一步:爬行,搜索引擎就是用一种特定规律软件追踪页面链接,由一个链接向另一个链接爬行
接着就是这样叫爬行。
第二步:抓取存储方面,搜索引擎通过蜘蛛追踪链接爬上页面,将爬上的数据保存在原页面数据库中。
第三步:预处理、搜索引擎从蜘蛛抓回网页、预处理各环节。
第四步:排名是指用户进入搜索框中的关键词之后,排名程序对索引库数据进行调用,向用户展示所述计算排名,在排名过程中直接和用户进行交互。
基于引擎内部资料,确定不同搜索引擎查得结果。如果你在检索时,有一个搜索引擎提供了某种相关的资料,那么它就会将这些相关资料显示到屏幕上,而您则可以通过这个搜索引擎来获得相应的结果。比如:某一种搜索引擎没有这种资料,你不会查到结果的。
扩展资料等:
界定
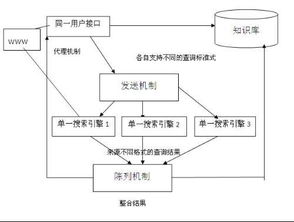
一种搜索引擎包括搜索器和索引器、检索器与用户接为四部分。其中,检索系统主要完成对网页内容进行分类、排序等任务。该搜索器具有漫游互联网的作用,查找并收集资料。索引器则负责把这些信息存储到数据库或其它系统中去,并将其显示给用户。索引器作用在于了解搜索器搜索到的信息,从其中提取索引项,一种索引表,用来指示文件和产生文件库。
检索器的作用就是基于用户查询,对索引库内的文件进行快速检出,执行文档和查询之间相关度评估,将待输出结果排序,以及实现了一定的用户相关性反馈机制。检索器要完成这些任务,必须有一个能满足不同需求和具有一定通用性的用户界面。用户接口具有录入用户查询功能、展示查询结果、为用户相关性提供反馈机制。
由来
一切搜索引擎的始祖,是1990年由Montreal的McGill University三名学生(Alan Emtage、Peter
Deutsch、Bill Wheelan)发明的Archie(Archie FAQ)。是个很有意思的东西。Alan Emtage和其他人想出研制一种能够使用文件名来查找文档的系统,就这样,Archie应运而生。
Archie首次实现了对互联网匿名FTP网站文件进行自动索引,但是这并不是一个真正意义上搜索引擎。如果你有一台计算机或者一台网络服务器的话,那么就有必要了解一些有关搜索引擎和检索方法了。Archie为可搜索FTP文件名清单,用户需要输入准确文件名进行查找,接着Archie将通知用户哪个FTP地址可下载文件。
由于Archie深受欢迎,受其启发,Nevada System Computing Services大学于1993年开发了一个Gopher(Gopher FAQ)搜索工具Veronica(Veronica FAQ)。这个软件提供了一种新的搜索方式,它能自动地从数据库中提取出用户感兴趣的数据集。Jughead是后来另一个Gopher搜索工具。
参考资料:百度百科–搜索引擎
搜索引擎有什么原理
搜索引擎的工作原理,可视为三步:从互联网抓取页面——→索引数据库的创建——→索引数据库内的搜索和排序。
●抓取互联网中的页面
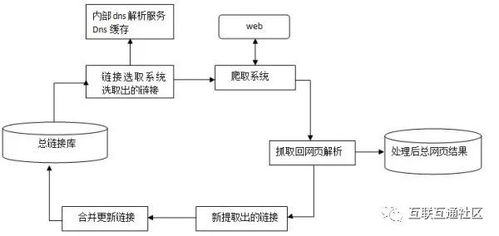
使用Spider系统程序,可以自动采集互联网中的页面,自动上网,并且顺着任意页面上的全部URL爬入另一个页面,重复上述步骤,将爬取的页面全部归集到。
·建立索引数据库
搜索引擎中的“网络机器人”或者“网络蜘蛛”,就是在网上开发的软件,它对Web空间进行遍历,并可在某一IP地址内对站点进行扫描,以及沿所述网络的链接由所述页面至所述其他页面,收集不同站点的网页资料。这种方法可以自动地对互联网上的信息和资源进行检索,从而获得需要的信息,如新闻、娱乐、体育等各种专题资料。是为了确保所收集到的信息是最新的,对已经抓取到的页面进行回访。由于采集到的网页数量巨大,因此要将这些网页信息保存下来就需要耗费很多时间和精力。由网络机器人或者网络蜘蛛收集到的页面,还需要别的程序来分析,按照某种相关度算法,通过大量计算来构建网页索引,以加入索引数据库。
·在索引数据库中搜索排序
名副其实的搜索引擎,通常指的是收集了因特网上几千万到几十亿个网页并对网页中的每一个词(即关键词)进行索引,为索引数据库构建全文搜索引擎。搜索引擎可以帮助人们快速准确地检索出自己所需信息和资源。用户在搜索某关键词时,凡页面内容含有此关键词的页面,均以搜索结果搜索。为了提高检索效率,搜索引擎一般采用基于关键字的搜索算法来获取所需要的信息,而这也就意味着搜索过程实际上就是把网页按其语义关系组织成一个个有序集合的过程。经复杂算法排序,这些结果会根据和搜索关键词相关度的高低进行排序。
何谓搜索引擎和搜索引擎原理
搜索引擎(Search Engine)就是按照某种策略、利用具体计算机程序收集互联网中的资料,经过资料的整理加工,对用户的检索服务,在所述系统中显示与所述用户检索有关的所述信息。搜索引擎作为一种专门用来搜索信息的技术工具,其作用在于帮助人们迅速地找到所需要的信息。搜索引擎由全文索引和目录索引两部分组成、元搜索引擎,垂直搜索引擎等、集合式搜索引擎等、门户搜索引擎和免费链接列表,等等。
其工作原理
第一步:爬行
搜索引擎就是用一种特定规律软件追踪页面链接,从一个链接爬到另一个链接,如同蜘蛛爬蜘蛛网,因此叫“蜘蛛”,又叫“机器人”。搜索引擎蜘蛛有很多种类型,它们都具有各自不同的功能和特点。搜索引擎蜘蛛爬行都会输入一些规律,它要求服从某些指令或文件内容。
第二步:抓取存储等
搜索引擎通过蜘蛛的追踪链接爬上页面,以及在原始页面数据库中保存爬行后的数据。在搜索过程中会发现许多相似或相近的网页,这些网页被称为“相似”网页,而它们之间又存在着不同的结构和语义信息,所以搜索引擎需要对它们进行分析比较后才能得出正确结果。其中页面数据和用户浏览器获取HTML完全相同。因此,搜索引擎的搜索结果就是被点击的网页,而不是网页中的信息。搜索引擎蜘蛛抓取网页的过程,同时还进行了一些重复内容检测,一碰到权重极低的站点,抄袭现象就非常严重、收集或复制,极有可能再也爬不起来。
第三步:预处理
搜索引擎对蜘蛛抓回网页并预处理各步。
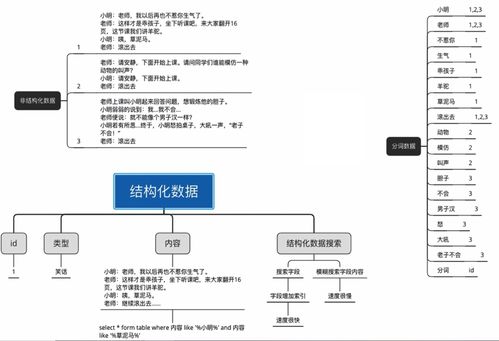
1
2
3
4。消除噪音(搜索引擎需要识别并消除这些噪声,比如版权声明文字、导航条、广告等……)
5
6
7。链接关系计算
8。特殊文件处理
除HTML文件之外,搜索引擎一般也可以对基于文字的各种文件类型进行抓取、索引等操作
PDF、Word、WPS、XLS、PPT、TXT文件等。当你打开一个网页时,屏幕上出现的就是这些文件了,如果你想查看它们的内容,就必须先将其分类存放。我们还常常在搜索结果里发现这些文件的类型。例如,搜索引擎可以从互联网上下载一些文件到本地的浏览器里去使用,或者把它们保存到一个文件夹里供用户查看和操作。但是搜索引擎仍然无法处理图片,视频和Flash等信息
这种非文字的内容也无法实现脚本及程序。
第四步:排名
当用户输入搜索框中的关键词时,排名程序对索引库数据进行调用,向用户展示所述计算排名,在排名过程中直接和用户进行交互。因此,搜索引擎的更新速度非常重要。然而由于搜索引擎数据量大,尽管可以做到每天更新少量内容,但通常搜索引擎排名规则是按日和按周排名、每月都会有不同程度的阶段性更新。
挑选吧
和网站内容有关
搜索次数和竞争较少
主关键词,范围不能过宽
主关键词中,有比较特别的关键词
具有商业价值
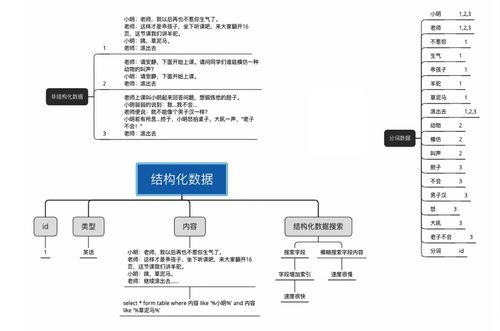
抽取文字
中文的分词
到停止词
去除噪声
去沉重的
正向索引等
倒排索引等
链接关系的计算
特殊文件的处理
百度搜索引擎是怎么做的啊?
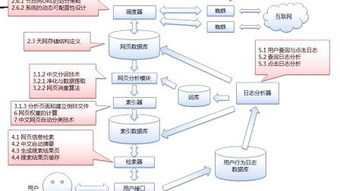
搜索引擎的基本工作原理
了解搜索引擎工作原理,对于我们在日常搜索应用以及网站提交推广等方面将大有裨益。
…………………………………………………………………………….
■全文搜索引擎等
在搜索引擎分类这一节中,我们已经提到了全文搜索引擎抽取网站中的信息来构建网页数据库这一思想。本文主要介绍了搜索引擎的信息内容采集功能以及如何实现搜索引擎的自动化信息收集功能。搜索引擎具有自动信息搜集功能,主要分为两类。一种是实时搜索,即每天都会有更新的信息源出现。一是定期搜索,即每隔一段时间(比如Google一般是28天),搜索引擎积极派遣“蜘蛛”节目,在某一IP地址内检索互联网站,一找到新址,在其数据库中自动抽取站点信息及网址添加。
二是报送网站搜索,也就是网站拥有者自愿将网址递交给搜索引擎,它会(2天到数月不等)定向地在一段时间内向您的站点发送“蜘蛛”程序,扫描您的站点,保存相关资料到数据库中,以供用户参考。这类方式一般被称为主动提交技术。由于近年来搜索引擎索引规则发生了很大变化,主动递交网址不能确保您的网址能够访问搜索引擎数据库,所以,现在最好的方法就是更多地获取外部链接,为搜索引擎提供了更多发现您,自动收录您站点的机会。
在用户使用关键词搜索消息的时候,搜索引擎搜索数据库,若查找到符合用户所需内容的站点,便用了专门的算法—一般都是基于网页上关键词匹配度,发生地点/频率,链接质量等等—统计每个页面相关度和排名等级,再按关联度的大小,这些网页链接被依次回传至用户。
…………………………………………………………………………….
■建立目录索引
目录索引和全文搜索引擎存在很多差异。
第一、搜索引擎是自动网站检索的一种,而且目录索引全靠手工操作。在这两种方法中,目录索引都是基于人工判断来实现对一个网页的选择和排序,而搜索结果的优劣最终取决于用户自己的评价。用户在提交站点之后,目录编辑人员将自己浏览您的站点,再依据一组自定评判标准,乃至编辑人员主观印象,决定要不要接受自己的站点。
二是搜索引擎在收录站点的时候,只要站点自身不违背相关规定,通常情况下,可以登陆成功。这就意味着搜索引擎在收录网站时不受任何限制,而且可以根据自己需要进行修改和添加。而且目录索引也有很多网站需求,有的时候,就算登陆了好几次,都不见得能成功。在一些大型搜索引擎中,甚至有专门为网站建立的“超级”目录或索引。特别像Yahoo!,这样的超链接只能访问一次,就连最普通的网页浏览也要经过注册才能访问。如此超级索引,登录就更难了。那么如何才能轻松地实现登录呢?(由于登录Yahoo!的难度最大,而它又是商家网络营销必争之地,所以我们会在后面用专门的篇幅介绍登录Yahoo雅虎的技巧)
另外,登陆搜索引擎后,我们通常不需要考虑对网站进行分类,而且,当你登录目录索引时,你必须把你的站点放在最适合你的目录下(Directory)。
最后从用户网页上自动抽取搜索引擎上各个站点相关信息,因此,从用户角度来看,我们有较大自主权;同时由于检索结果以列表形式出现,因此用户在选择自己感兴趣的信息源时,也有了比较大的自由。并且目录索引需要人工另填网站信息,并有种种局限。这样做不仅会造成人力的浪费,还会使检索效率下降。更甚者,假如员工觉得你递交了网站目录、网站信息不当,他能在任何时候调整它,当然,事前并不与您讨论。
目录索引从字面上理解,是指网站被分门别类保存到对应目录下的索引,所以当使用者查询资料的时候,可选的关键词搜索,还可以根据分类目录进行层层搜索。由于不同类型的搜索引擎对同一信息内容所采用的检索策略各不相同,所以其提供给用户的网页排序也不相同。如果用关键词检索,返回结果与搜索引擎相同,还按信息的关联程度对站点进行了编排,只是,这里面的人为因素多了一些。若根据分层目录进行搜索,某个目录下的网站排名,则取决于标题字母顺序(也有例外)。
当前搜索引擎和目录索引之间存在着一种互相融合和渗透的倾向。许多网站都利用自己开发的专门的检索工具来进行信息资源的检索。本来有些纯全文搜索引擎,如今也推出了目录搜索,例如,Google借用Open Directory目录提供分类查询。而像Yahoo!之类的大型网络搜索引擎还可以向用户推荐特定的书目资源。这些老牌目录索引是通过和Google和其他搜索引擎的合作来扩展搜索范围的(注)。不过这些目录检索功能还停留在传统的静态搜索阶段。默认的搜索模式中,有些目录类搜索引擎会先返回与其目录相匹配的站点,例如,国内的搜狐,新浪,网易;其次才会返回与自身相关的网站信息。而其他默认为Yahoo等网页搜索。
(注):百度也是一样地
原创文章,作者:聚禄鼎,如若转载,请注明出处:https://www.xxso.cn/28812.html