
爬虫工具有哪些


网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),就是根据某种规律,从万维网信息中自动捕获程序或脚本。其他几个不常用的名称包括蚂蚁,自动索引等、模拟程序或蠕虫。目前国内对网络爬虫研究较少,但它已经越来越受到人们重视和关注。中文名称网络爬虫中文名称web crawler别名网络蜘蛛用途根据需要访问万维网信息背景伴随着网络的飞速发展,万维网成了海量信息载体,如何高效地抽取和使用这类信息,成了一大难题。目前最常用的方法就是人工搜索,这种方法需要耗费大量时间和精力并且效率低下。搜索引擎(Search Engine),比如,传统通用搜索引擎AltaVista和Yahoo!它以其独特的方式为广大网民提供了丰富而又全面的信息源。以及Google等作为帮助人们进行信息检索的手段,成了用户进入万维网时的门户与指南。目前已经有很多通用型搜索引擎被开发出来用于万维信息源搜索。但这些通用性搜索引擎都有其局限性,例如:(1)领域不一、不同后台的用户通常有不同的检索目的与要求,通用搜索引擎返回结果中包含了很多用户并不在意的页面。(2)通用搜索引擎以最大限度地提高网络覆盖率为目的,搜索引擎服务器资源的有限性和网络数据资源的无限性,这对矛盾会更加深化。(3)万维网的数据形式不断丰富,网络技术也在不断地发展,图片,数据库,音频等、视频多媒体和其他不同的数据层出不穷,通用搜索引擎在处理这类信息含量稠密、有一定架构的数据时,通常是束手无策,无法被很好的找到并得到。(4)通用搜索引擎多数提供以关键字为单位进行检索,基于语义信息进行查询很难得到支持。
爬虫类工具的用法是如何解决小白的问题
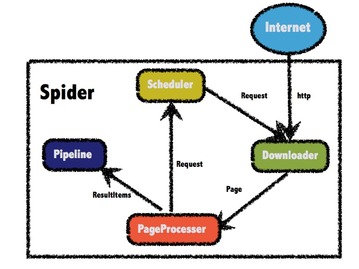
主要就是先把html的页面爬回去
再利用正则表达式进行匹配
python的话涉及到urllib,urllib2,re等模块
java的话涉及到httpurlconnection,pattern,match等类 java的话涉及到httpurlconnection,pattern,match等类
爬虫的框架还有很多种,但是这个要根据个人的想法而定,普通新手要想直接学习框架是要有耐心的
有关框架方面的事情,可直接去百度某某编程语言中有哪些优秀爬虫框架

是否有像网络爬虫一样能抓w的数据抓工具
ForeSpider数据采集系统是天津市前嗅网络科技有限公司自主知识产权的通用互联网数据采集软件。它以其简单易学的编程方式和丰富的数据类型成为目前国内最流行的数据采集器之一。该软件几乎能收集到互联网的全部公开数据,通过可视化操作流程从建表到筛选、收集至入库一步完成。支持正则表达式的运算,更具功能强大面向对象脚本语言系统。
台式机单机采集能力可达到4000-8000万台,日采集能力达500万人次以上。在海量数据处理上,单机已无法满足需求。服务器单机集群环境采集能力高达8亿-16亿,日采集能力在4000万人次以上。基于分布式架构和海量存储优势,台式机可以在任何时间任意地点完成对各种应用数据的实时收集,并通过云平台进行集中处理分析,实现大数据分析、挖掘及可视化展现。在并行的条件下,可以支持超过百亿级的数据链接,堪比百度这样的搜索引擎系统。
软件的特点:
一。通用性:能抓取互联网中接近100%的信息
1。
2。支持Cookie技术。
3。
4。支持HTTPS安全协议。
5。支持OAuth认证。
6。支持POST请求。
7。支持搜索栏的关键词搜索采集。
8。支持JS动态生成页面收藏。
9。支持IP代理采集。
10。支持图片采集功能。
11。支持本地目录收藏。
12。内置面向对象脚本语言系统、配置脚本可收集互联网信息近100%。
二。高质量数据:精准采集所需数据
1。自主知识产权JS引擎,精准采集。
2。内部集成数据库,数据直接采集入库。
3。内部创建数据表结构,抓取数据后直接存入数据库相应字段。
4。根据dom结构自动过滤不相关信息。
5。通过模板配置链接抽取和数据抽取,目标网站的所有可见内容均可采集,智能过滤无关信息。
6。采集前数据可预览采集,随时调整模板配置,提升数据精度和质量。
7。字段的数据支持多种处理方式。
8。支持正则表达式,精准处理数据。
9。支持脚本配置,精确处理字段的数据。
三
1.C++编制的爬虫具有极好的采集性能。
2。
3、台式机单机采集能力可达4000-8000万,日采集能力超过500万。
4、服务器单机集群环境采集能力可达8亿-16亿,日采集能力超过4000万。
5。并行情况下可支撑百亿以上规模数据链接,堪与百度等搜索引擎系统媲美。
6。
四。简单高效:节省70%配置时间
1。完全可视化的配置界面,操作流程顺畅简易。
2。基本上无需计算机基础,代码薄弱的人也能很快上手,操作门槛较低,为企业爬虫工程师节约了成本。
3。过滤采集入库一步到位,集成表结构配置、链接过滤、字段取值、采集预览、数据入库。
4。
5。内置浏览器,字段取值直接在浏览器上可视化定位。
五
1。内置数据库,数据采集完毕直接存储入库。
2。在软件内部创建数据表和数据字段,直接关联数据库。
3。采集数据时配置数据模板,网页数据直接存入对应数据表的相应字段。
4。正式采集之前预览采集结果,有问题及时修正配置。
5。数据表可以导出为csv格式,在Excel工作表中浏览。
6。
六。智能:智能模拟用户和浏览器行为
1。智能模拟浏览器和用户行为,突破反爬虫限制。
2。自动抓取网页的各类参数和下载过程的各类参数。
3..支持动态IP代理加速功能,对无效IP代理进行智能过滤,提高代理利用效率及采集质量。
4。支持动态调整数据抓取策略,多种策略让您的数据无需重采,不再担心漏采,数据采集更智能。
5。
6。
7。设置文件大小阈值,自动过滤超大文件。
8、自由设置浏览器是否加速,自动过滤页面flash等无关内容。
9。智能定位字段取值区域。
10。取值区域可基于字符串特征进行自动定位。
11。智能识别表格多值,表格数据可完美存储在对应字段中。
七
1。数据采集完全在本地进行,保证数据安全性。
2。提供大量免费的各个网站配置模板在线下载,用户可以自由导入导出。
3。
4。
5。为用户提供各类高端定制化服务,全方位来满足用户的数据需求。
除了网络爬虫技术之外,是否还有别的工具可以自动抓取数据?

网络爬虫作用有限噢,只会爬取网页内容,即BS端资料噢。
如果你想在软件系统即CS端收集数据,可以使用博为小帮软件机器人喔。
小帮BS,CS端数据均可收集,全自动操作,仅需简单配置。通过这个软件就可以完成整个系统的所有功能,并且能够实现远程监控,报警等多种服务功能。与手工收集数据相比,小帮效率大提高!
原创文章,作者:聚禄鼎,如若转载,请注明出处:https://www.xxso.cn/2388.html