
搜索引擎的工作原理是什么?
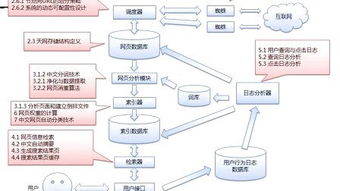

搜索引擎的工作原理总共有四步:
第一步:爬行,搜索引擎是通过一种特定规律的软件跟踪网页的链接,从一个链接爬到另外一个链
接,所以称为爬行。
第二步:抓取存储,搜索引擎是通过蜘蛛跟踪链接爬行到网页,并将爬行的数据存入原始页面数据库。
第三步:预处理,搜索引擎将蜘蛛抓取回来的页面,进行各种步骤的预处理。
第四步:排名,用户在搜索框输入关键词后,排名程序调用索引库数据,计算排名显示给用户,排名过程与用户直接互动的。
不同的搜索引擎查出来的结果是根据引擎内部资料所决定的。比如:某一种搜索引擎没有这种资料,您就查询不到结果。
扩展资料:
定义
一个搜索引擎由搜索器、索引器、检索器和用户接四个部分组成。搜索器的功能是在互联网中漫游,发现和搜集信息。索引器的功能是理解搜索器所搜索的信息,从中抽取出索引项,用于表示文档以及生成文档库的索引表。
检索器的功能是根据用户的查询在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序,并实现某种用户相关性反馈机制。用户接口的作用是输入用户查询、显示查询结果、提供用户相关性反馈机制。
起源
所有搜索引擎的祖先,是1990年由Montreal的McGill University三名学生(Alan Emtage、Peter
Deutsch、Bill Wheelan)发明的Archie(Archie FAQ)。Alan Emtage等想到了开发一个可以用文件名查找文件的系统,于是便有了Archie。
Archie是第一个自动索引互联网上匿名FTP网站文件的程序,但它还不是真正的搜索引擎。Archie是一个可搜索的FTP文件名列表,用户必须输入精确的文件名搜索,然后Archie会告诉用户哪一个FTP地址可以下载该文件 。
由于Archie深受欢迎,受其启发,Nevada System Computing Services大学于1993年开发了一个Gopher(Gopher FAQ)搜索工具Veronica(Veronica FAQ)。Jughead是后来另一个Gopher搜索工具。
参考资料来源:百度百科-搜索引擎
搜索引擎工作原理是什么??
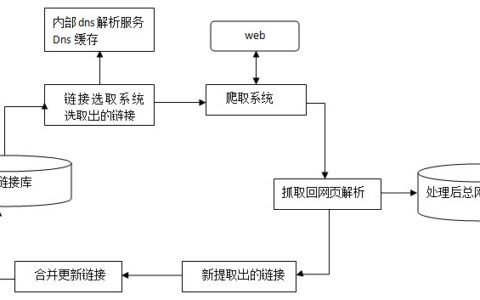
搜索引擎的基本工作原理包括如下三个过程:首先在互联网中发现、搜集网页信息;同时对信息进行提取和组织建立索引库;再由检索器根据用户输入的查询关键字,在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序,并将查询结果返回给用户。
1、抓取网页。每个独立的搜索引擎都有自己的网页抓取程序爬虫(spider)。爬虫Spider顺着网页中的超链接,从这个网站爬到另一个网站,通过超链接分析连续访问抓取更多网页。被抓取的网页被称之为网页快照。由于互联网中超链接的应用很普遍,理论上,从一定范围的网页出发,就能搜集到绝大多数的网页。
2、处理网页。搜索引擎抓到网页后,还要做大量的预处理工作,才能提供检索服务。其中,最重要的就是提取关键词,建立索引库和索引。其他还包括去除重复网页、分词(中文)、判断网页类型、分析超链接、计算网页的重要度/丰富度等。
3、提供检索服务。用户输入关键词进行检索,搜索引擎从索引数据库中找到匹配该关键词的网页;为了用户便于判断,除了网页标题和URL外,还会提供一段来自网页的摘要以及其他信息。
搜索引擎的原理是什么
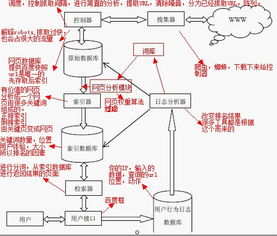
■ 全文搜索引擎
在搜索引擎分类部分我们提到过全文搜索引擎从网站提取信息建立网页数据库的概念。搜索引擎的自动信息搜集功能分两种。一种是定期搜索,即每隔一段时间(比如Google一般是28天),搜索引擎主动派出“蜘蛛”程序,对一定IP地址范围内的互联网站进行检索,一旦发现新的网站,它会自动提取网站的信息和网址加入自己的数据库。
另一种是提交网站搜索,即网站拥有者主动向搜索引擎提交网址,它在一定时间内(2天到数月不等)定向向你的网站派出“蜘蛛”程序,扫描你的网站并将有关信息存入数据库,以备用户查询。由于近年来搜索引擎索引规则发生了很大变化,主动提交网址并不保证你的网站能进入搜索引擎数据库,因此目前最好的办法是多获得一些外部链接,让搜索引擎有更多机会找到你并自动将你的网站收录。
当用户以关键词查找信息时,搜索引擎会在数据库中进行搜寻,如果找到与用户要求内容相符的网站,便采用特殊的算法——通常根据网页中关键词的匹配程度,出现的位置/频次,链接质量等——计算出各网页的相关度及排名等级,然后根据关联度高低,按顺序将这些网页链接返回给用户。
…………………………………………………………………………….
■ 目录索引
与全文搜索引擎相比,目录索引有许多不同之处。
首先,搜索引擎属于自动网站检索,而目录索引则完全依赖手工操作。用户提交网站后,目录编辑人员会亲自浏览你的网站,然后根据一套自定的评判标准甚至编辑人员的主观印象,决定是否接纳你的网站。
其次,搜索引擎收录网站时,只要网站本身没有违反有关的规则,一般都能登录成功。而目录索引对网站的要求则高得多,有时即使登录多次也不一定成功。尤其象Yahoo!这样的超级索引,登录更是困难。(由于登录Yahoo!的难度最大,而它又是商家网络营销必争之地,所以我们会在后面用专门的篇幅介绍登录Yahoo雅虎的技巧)
此外,在登录搜索引擎时,我们一般不用考虑网站的分类问题,而登录目录索引时则必须将网站放在一个最合适的目录(Directory)。
最后,搜索引擎中各网站的有关信息都是从用户网页中自动提取的,所以用户的角度看,我们拥有更多的自主权;而目录索引则要求必须手工另外填写网站信息,而且还有各种各样的限制。更有甚者,如果工作人员认为你提交网站的目录、网站信息不合适,他可以随时对其进行调整,当然事先是不会和你商量的。
目录索引,顾名思义就是将网站分门别类地存放在相应的目录中,因此用户在查询信息时,可选择关键词搜索,也可按分类目录逐层查找。如以关键词搜索,返回的结果跟搜索引擎一样,也是根据信息关联程度排列网站,只不过其中人为因素要多一些。如果按分层目录查找,某一目录中网站的排名则是由标题字母的先后顺序决定(也有例外)。
目前,搜索引擎与目录索引有相互融合渗透的趋势。原来一些纯粹的全文搜索引擎现在也提供目录搜索,如Google就借用Open Directory目录提供分类查询。而象 Yahoo! 这些老牌目录索引则通过与Google等搜索引擎合作扩大搜索范围(注)。在默认搜索模式下,一些目录类搜索引擎首先返回的是自己目录中匹配的网站,如国内搜狐、新浪、网易等;而另外一些则默认的是网页搜索,如Yahoo。
参考资料:http://www.se-express .康姆/about/about2.htm
搜索引擎的搜索原理是什么?
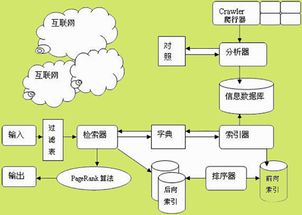
搜索引擎的工作原理:
1、搜集信息
搜索引擎的信息搜集基本都是自动的。
搜索引擎利用称为网络蜘蛛的自动搜索机器人程序来连上每一个网页上的超链接。
机器人程序根据网页连到其中的超链接,就像日常生活中所说的一传十,十传百,从少数几个网页开始,连到数据库上所有到其他网页的链接。
理论上,若网页上有适当的超链接,机器人便可以遍历绝大部分网页。
2、整理信息
搜索引擎整理信息的过程称为“创建索引”。
搜索引擎不仅要保存搜集起来的信息,还要将它们按照一定的规则进行编排。这样,搜索引擎根本不用重新翻查它所有保存的信息而迅速找到所要的资料。
3、接受查询
用户向搜索引擎发出查询,搜索引擎接受查询并向用户返回资料。
搜索引擎每时每刻都要接到来自大量用户的几乎是同时发出的查询,它按照每个用户的要求检查自己的索引,在极短时间内找到用户需要的资料,并返回给用户。
目前,搜索引擎返回主要是以网页链接的形式提供的,这样通过这些链接,用户便能到达含有自己所需资料的网页。
通常搜索引擎会在这些链接下提供一小段来自这些网页的摘要信息以帮助用户判断此网页是否含有自己需要的内容。
搜索引擎是怎样的原理
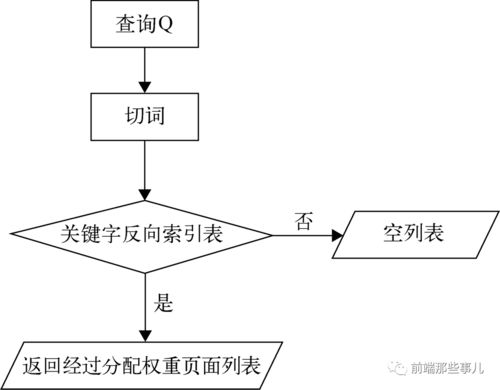
【工作原理】
1、抓取网页
每个独立的搜索引擎都有自己的网页抓取程序(spider)。Spider顺着网页中的超链接,连续地抓取网页。由于互联网中超链接的应用很普遍,理论上,从一定范围的网页出发,就能搜集到绝大多数的网页。
2、处理网页
搜索引擎抓到网页后,还要做大量的预处理工作,才能提供检索服务。其中,最重要的就是提取关键词,建立索引文件。其他还包括去除重复网页、分析超链接、计算网页的重要度。
3、提供检索服务
用户输入关键词进行检索,搜索引擎从索引数据库中找到匹配该关键词的网页;为了用户便于判断,除了网页标题和URL外,还会提供一段来自网页的摘要以及其他信息。
全文搜索引擎
在搜索引擎分类部分我们提到过全文搜索引擎从网站提取信息建立网页数据库的概念。搜索引擎的自动信息搜集功能分两种。一种是定期搜索,即每隔一段时间(比如Google一般是28天),搜索引擎主动派出“蜘蛛”程序,对一定IP地址范围内的互联网站进行检索,一旦发现新的网站,它会自动提取网站的信息和网址加入自己的数据库。
另一种是提交网站搜索,即网站拥有者主动向搜索引擎提交网址,它在一定时间内(2天到数月不等)定向向你的网站派出“蜘蛛”程序,扫描你的网站并将有关信息存入数据库,以备用户查询。由于近年来搜索引擎索引规则发生了很大变化,主动提交网址并不保证你的网站能进入搜索引擎数据库,因此目前最好的办法是多获得一些外部链接,让搜索引擎有更多机会找到你并自动将你的网站收录。
当用户以关键词查找信息时,搜索引擎会在数据库中进行搜寻,如果找到与用户要求内容相符的网站,便采用特殊的算法——通常根据网页中关键词的匹配程度,出现的位置/频次,链接质量等——计算出各网页的相关度及排名等级,然后根据关联度高低,按顺序将这些网页链接返回给用户。
目录索引
与全文搜索引擎相比,目录索引有许多不同之处。
首先,搜索引擎属于自动网站检索,而目录索引则完全依赖手工操作。用户提交网站后,目录编辑人员会亲自浏览你的网站,然后根据一套自定的评判标准甚至编辑人员的主观印象,决定是否接纳你的网站。
其次,搜索引擎收录网站时,只要网站本身没有违反有关的规则,一般都能登录成功。而目录索引对网站的要求则高得多,有时即使登录多次也不一定成功。尤其象Yahoo!这样的超级索引,登录更是困难。
此外,在登录搜索引擎时,我们一般不用考虑网站的分类问题,而登录目录索引时则必须将网站放在一个最合适的目录(Directory)。
最后,搜索引擎中各网站的有关信息都是从用户网页中自动提取的,所以用户的角度看,我们拥有更多的自主权;而目录索引则要求必须手工另外填写网站信息,而且还有各种各样的限制。更有甚者,如果工作人员认为你提交网站的目录、网站信息不合适,他可以随时对其进行调整,当然事先是不会和你商量的。
目录索引,顾名思义就是将网站分门别类地存放在相应的目录中,因此用户在查询信息时,可选择关键词搜索,也可按分类目录逐层查找。如以关键词搜索,返回的结果跟搜索引擎一样,也是根据信息关联程度排列网站,只不过其中人为因素要多一些。如果按分层目录查找,某一目录中网站的排名则是由标题字母的先后顺序决定(也有例外)。
目前,搜索引擎与目录索引有相互融合渗透的趋势。原来一些纯粹的全文搜索引擎现在也提供目录搜索,如Google就借用Open Directory目录提供分类查询。而象 Yahoo! 这些老牌目录索引则通过与Google等搜索引擎合作扩大搜索范围(注)。在默认搜索模式下,一些目录类搜索引擎首先返回的是自己目录中匹配的网站,如国内搜狐、新浪、网易等;而另外一些则默认的是网页搜索,如Yahoo。
【搜索引擎的发展史】
1990年,加拿大麦吉尔大学(University of McGill)计算机学院的师生开发出Archie。当时,万维网(World Wide Web)还没有出现,人们通过FTP来共享交流资源。Archie能定期搜集并分析FTP服务器上的文件名信息,提供查找分别在各个FTP主机中的文件。用户必须输入精确的文件名进行搜索,Archie告诉用户哪个FTP服务器能下载该文件。虽然Archie搜集的信息资源不是网页(HTML文件),但和搜索引擎的基本工作方式是一样的:自动搜集信息资源、建立索引、提供检索服务。所以,Archie被公认为现代搜索引擎的鼻祖。
搜索引擎的起源:
所有搜索引擎的祖先,是1990年由Montreal的McGill University三名学生(Alan Emtage、Peter Deutsch、Bill Wheelan)发明的Archie(Archie FAQ)。Alan Emtage等想到了开发一个可以用文件名查找文件的系统,于是便有了Archie。Archie是第一个自动索引互联网上匿名FTP网站文件的程序,但它还不是真正的搜索引擎。Archie是一个可搜索的FTP文件名列表,用户必须输入精确的文件名搜索,然后Archie会告诉用户哪一个FTP地址可以下载该文件。 由于Archie深受欢迎,受其启发,Nevada System Computing Services大学于1993年开发了一个Gopher(Gopher FAQ)搜索工具Veronica(Veronica FAQ)。Jughead是后来另一个Gopher搜索工具。
原创文章,作者:聚禄鼎,如若转载,请注明出处:https://www.xxso.cn/163078.html